添加依赖
pnpm add langchain @langchain/core #添加langchain核心库
pnpm add @langchain/openai #这边的示例使用openai的作为展示
pnpm add dotenv #添加dotenv作为配置库
|
设置环境变量
创建一个.env文件,写入
对应的openai的apikey,以及如果使用代理的话,对应的代理地址。当然如果没有使用代理的话,就不需要这一项。
调用大语言模型进行对话
import { ChatOpenAI } from '@langchain/openai'
import { HumanMessage, SystemMessage } from '@langchain/core/messages'
import 'dotenv/config'
const model = new ChatOpenAI({
modelName: 'o3-mini',
openAIApiKey: process.env.API_KEY,
configuration: {
baseURL: process.env.BASE_URL,
},
})
const messages = [
new SystemMessage('将下面的话从中文翻译成英语'),
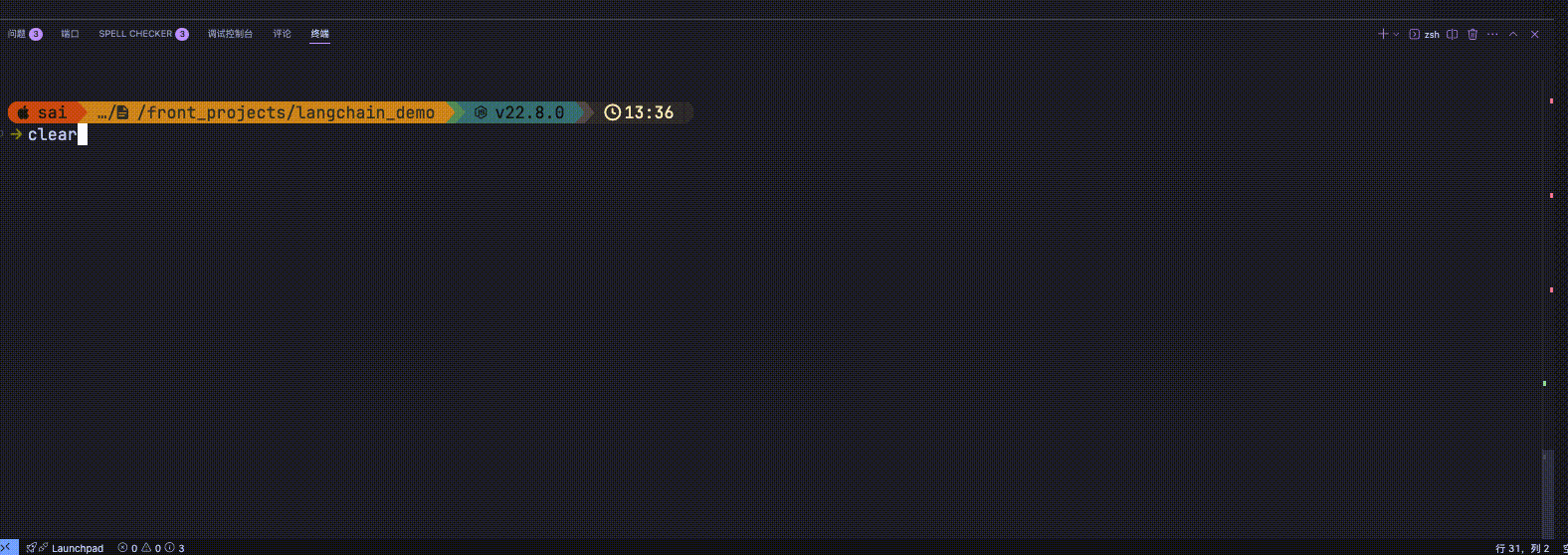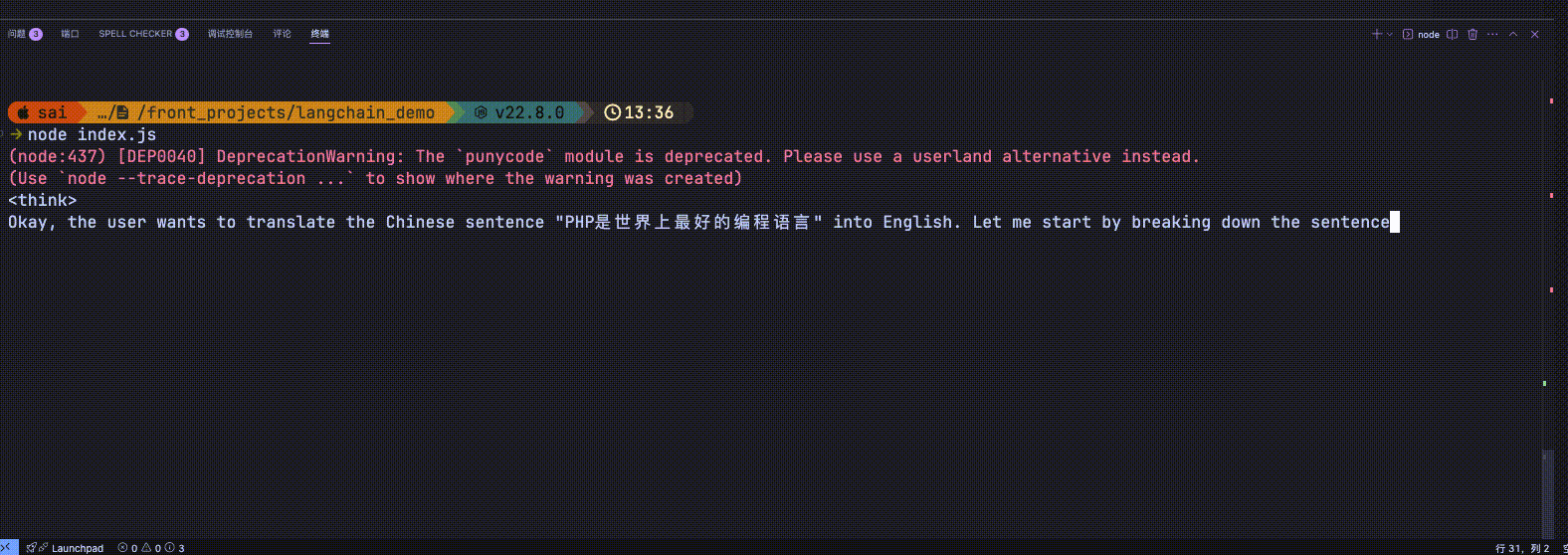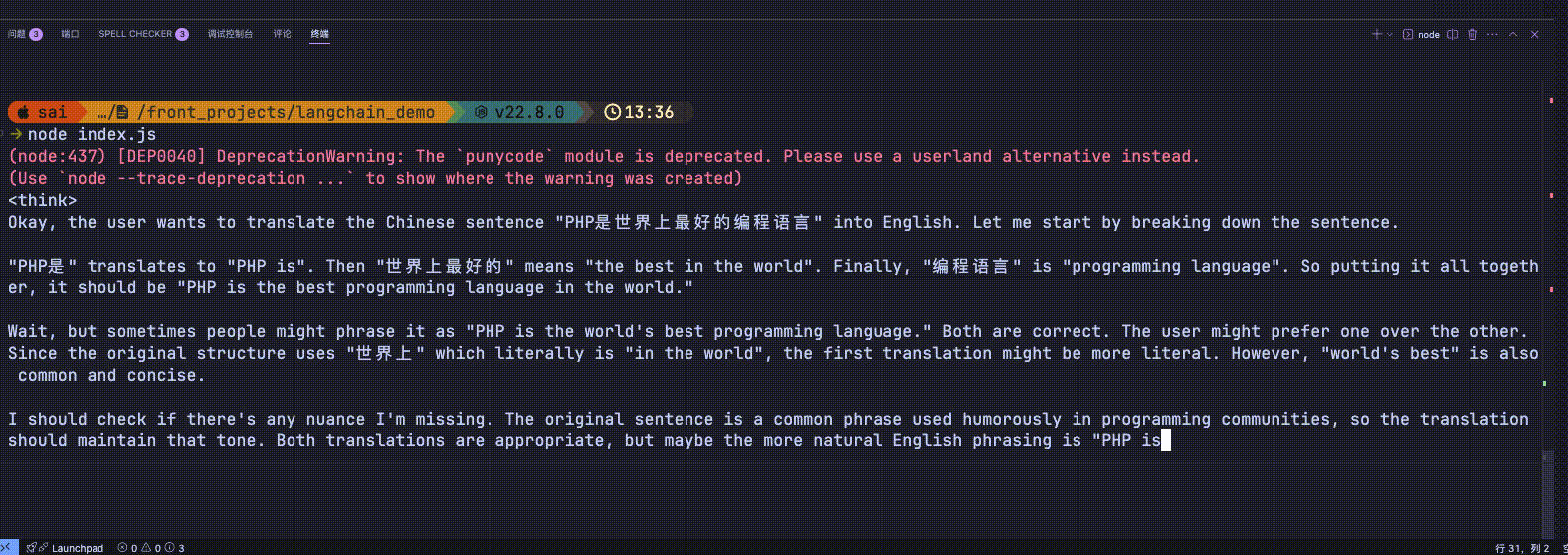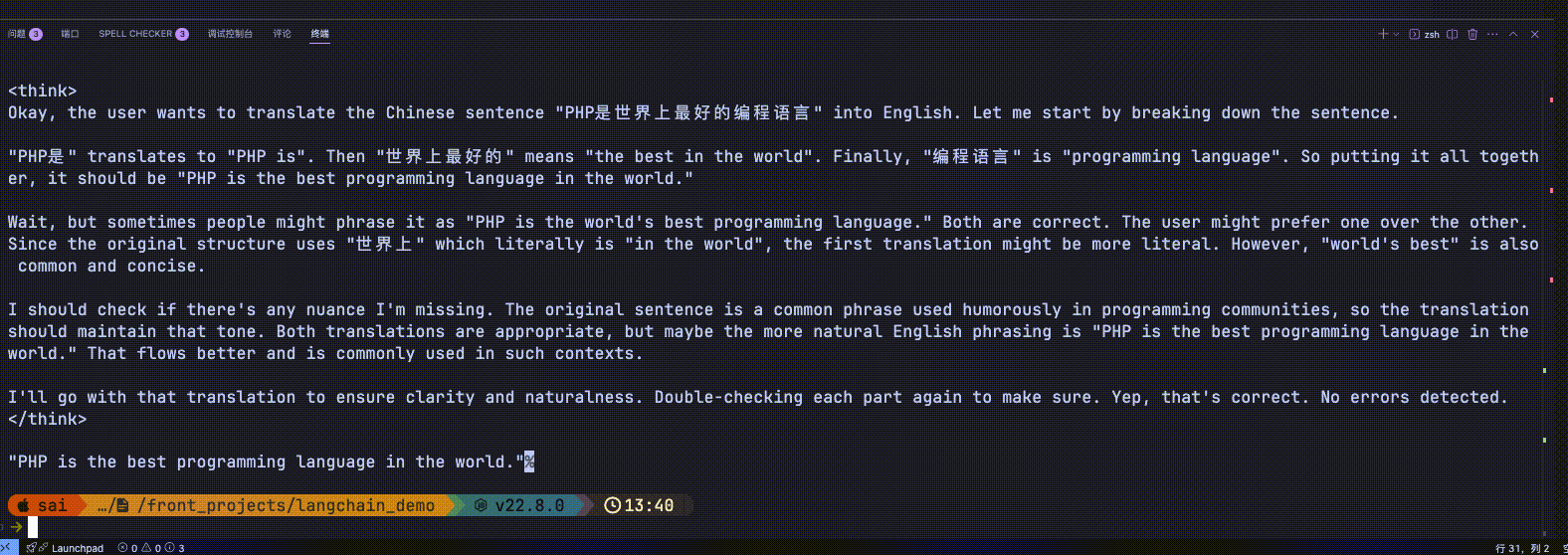
new HumanMessage('PHP是世界上最好的编程语言'),
]
const result = await model.invoke(messages)
console.log(result.content)
|
输出

使用其他的方式构建对话Message
const messages = [
new SystemMessage('将下面的话从中文翻译成英语'),
new HumanMessage('PHP是世界上最好的编程语言'),
]
const messages = [
{ role: 'system', content: '将下面的话从中文翻译成英语' },
{ role: 'user', content: 'PHP是世界上最好的编程语言' },
]
|
上面这两种写法是等价的,将对应的Message对象简化为包含role和content的对象。
Message对象分为:
- SystemMessage: 对应的system这种role
- HumanMessage: 对应的user这种role
- AIMessage: 对应assistant这种role
- AIMessageChunk: 对应assistant这种role,用于stream模式下的回复
- ToolMessage: 对应tool这种role
进一步简化,可以将对象换成数组,数组的第一个元素就是role,第二个元素就是content
const messages = [
['system', '将下面的话从中文翻译成英语'],
['user', 'PHP是世界上最好的编程语言'],
]
|
这样也是一样的。
Streaming 流式传输
chat model的运行是异步的,提供了一个streaming模式调用。这样返回的内容可以一段一段返回,而不是等到完全生成之后,在一次性返回。
const stream = await model.stream(messages)
for await (const chunk of stream) {
process.stdout.write(chunk.content)
}
|
为了演示的更加明显这里使用了deepseek-r1模型(deepseek-r1模型带长思考)
Prompt Templates 提示词模板
为了更好的去复用一些提示词,比如我们想让用户输入的内容从中文翻译成英文,下次的时候想要从中文翻译成日文,再下次可能是法文等等,其中变化的其实只有一小部分,这一小部分我们可以抽离出来作为变量。
import { ChatPromptTemplate } from '@langchain/core/prompts'
const systemTemplate = '将下面的内容从中文翻译成{language}'
const promptTemplate = ChatPromptTemplate.fromMessages([
['system', systemTemplate],
['user', '{text}'],
])
const promptValue = await promptTemplate.invoke({
language: '日文',
text: '好好学习,天天向上',
})
const stream = await model.stream(promptValue)
for await (const chunk of stream) {
process.stdout.write(chunk.content)
}
|
效果

总结
这样一个简单的LLM应用就完成了,在langchain的帮助下,我们仅需要关心使用的模型,一些提示词之类的,将调用和解析模型返回之间的过程都省去了。