添加依赖 pnpm add @langchain/core @langchain/langgraph uuid pnpm add dotenv
创建.env文件,并添加 API_KEY 和 BASE_URL(如果没有使用代理,就不用添加) 两个配置。
创建一个简单对话 import { ChatOpenAI } from '@langchain/openai' import 'dotenv/config' const llm = new ChatOpenAI ({ modelName : 'o3-mini' , openAIApiKey : process.env .API_KEY , configuration : { baseURL : process.env .BASE_URL , }, temperature : 0 , }) const resp = await llm.invoke ([ { role : 'user' , content : 'Hi im bob' , }, ]) console .log (resp.content )
返回
问题的产生 如果我们再询问一下问题
await llm.invoke ([{ role : "user" , content : "What's my name" }])
返回内容如下,可见模型并不知道我们的名字
但如果我们带了上下文内容
await llm.invoke ([ { role : "user" , content : "Hi! I'm Bob" }, { role : "assistant" , content : "Hello Bob! How can I assist you today?" }, { role : "user" , content : "What's my name?" }, ])
我们得到了很好的回应,可见让大模型与我们正常进行对话的基本要求在于消息的持久化
Message Persistence 消息持久化 LangGraph实现了一个内置的持久层,使其成为支持多个轮次对话的理想选择。它让我们能够自动持久化消息历史记录,从而简化多轮次对话应用的开发。
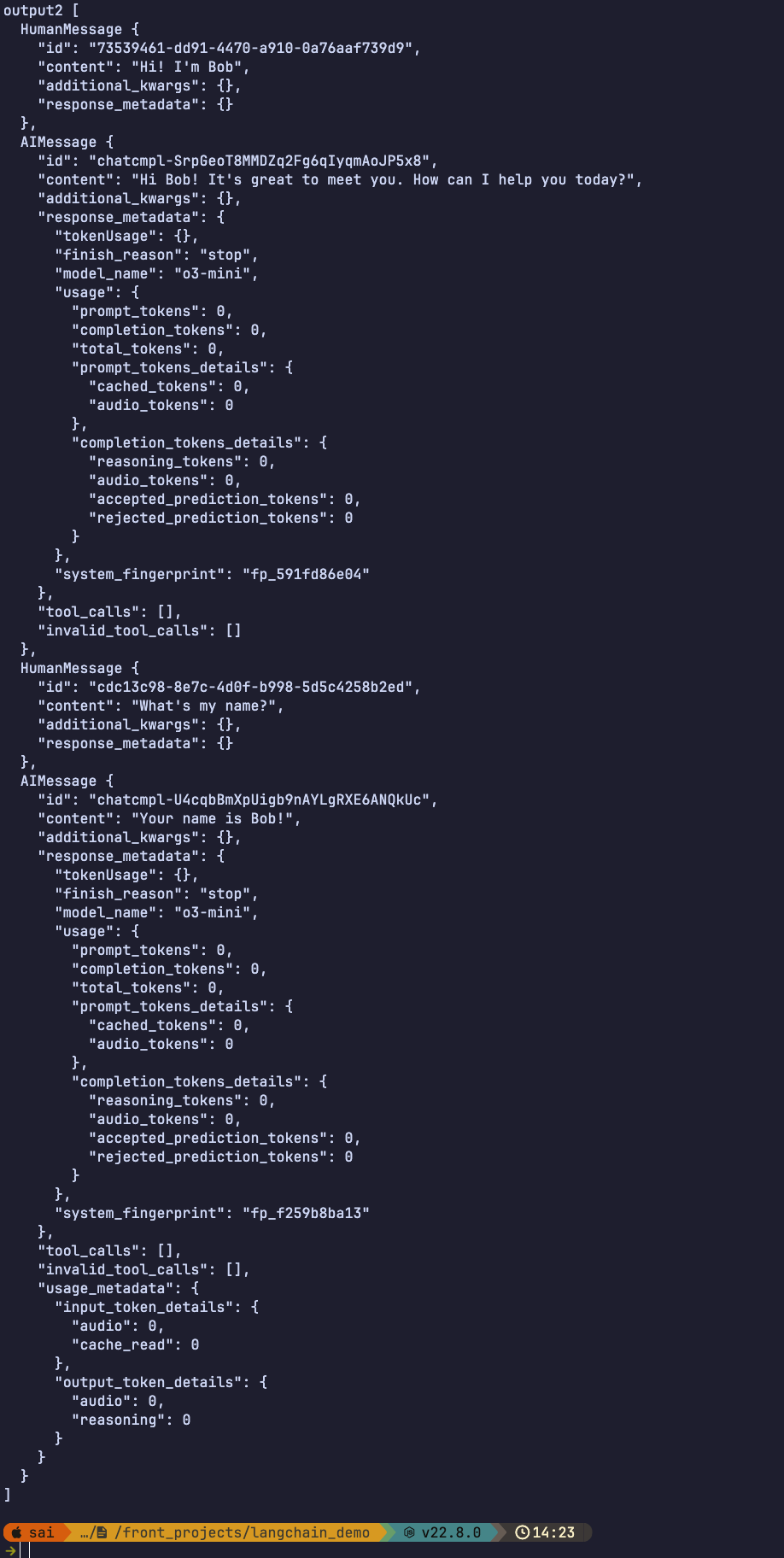
import { START , END , MessagesAnnotation , StateGraph , MemorySaver , } from '@langchain/langgraph' import { v4 as uuidv4 } from 'uuid' const callModel = async (state ) => { const response = await llm.invoke (state.messages ) return { messages : response } } const workflow = new StateGraph (MessagesAnnotation ) .addNode ('model' , callModel) .addEdge (START , 'model' ) .addEdge ('model' , END ) const memory = new MemorySaver ()const app = workflow.compile ({ checkpointer : memory })const config = { configurable : { thread_id : uuidv4 () } }const input = [{ role : 'user' , content : "Hi! I'm Bob" }]let output = await app.invoke ({ messages : input }, config)console .log ('output' , output.messages [output.messages .length - 1 ].content )const input2 = [{ role : 'user' , content : "What's my name?" }]output = await app.invoke ({ messages : input2 }, config) console .log ('output2' , output.messages [output.messages .length - 1 ].content )
返回结果可见模型已经能够获取到了上下文来支持进行多轮对话了
打印 output.messages 可以看到每轮的对话都被放入了messages中了
切换别的thread_id 一旦我们切换别的thread_id时,就会发现进行了新的对话了
const config2 = { configurable : { thread_id : uuidv4 () } }const input2 = [{ role : 'user' , content : "What's my name?" }]output = await app.invoke ({ messages : input2 }, config2) console .log ('output2' , output.messages [output.messages .length - 1 ].content )
结果可以看到切换了thread_id就得不到原先的上下文了,也就记不住之前的对话内容了
返回原先的对话 不用担心这个问题,因为我们在内存中持久化了原先的对话,因此我们可以通过原先的thread_id将对话切换回来
output = await app.invoke ({ messages : input2 }, config) console .log ('output3' , output.messages [output.messages .length - 1 ].content )
可以看到在第三次对话中,又能获取到之前的聊天内容了
Prompt Templates 提示词模板 添加提示词模板,会让一些输入可以进行复用以及简化一些输入
const promptTemplate = ChatPromptTemplate .fromMessages ([ ['system' ,'You talk like a pirate. Answer all questions to the best of your ability' ], ['placeholder' , '{messages}' ], ]) const callModel = async (state ) => { const prompt = await promptTemplate.invoke (state) const response = await llm.invoke (prompt) return { messages : response } } const input = [{ role : 'user' , content : "Hi! I'm Jim" }]let output = await app.invoke ({ messages : input }, config)console .log (output.messages [output.messages .length - 1 ].content )const input2 = [{ role : 'user' , content : 'What is my name?' }]output = await app.invoke ({ messages : input2 }, config) console .log (output.messages [output.messages .length - 1 ].content )
结果如下,可以发现返回内容都是以海盗的口吻说的
增加点复杂度 const promptTemplate2 = ChatPromptTemplate .fromMessages ([ [ "system" , "You are a helpful assistant. Answer all questions to the best of your ability in {language}." , ], ["placeholder" , "{messages}" ], ]); const GraphAnnotation = Annotation .Root ({ ...MessagesAnnotation .spec , language : Annotation (), }) const callModel = async (state ) => { const prompt = await promptTemplate2.invoke (state) const response = await llm.invoke (prompt) return { messages : response } } const workflow = new StateGraph (GraphAnnotation ) .addNode ('model' , callModel) .addEdge (START , 'model' ) .addEdge ('model' , END ) const memory = new MemorySaver ()const app = workflow.compile ({ checkpointer : memory })const config = { configurable : { thread_id : uuidv4 () } }const input = [{ role : 'user' , content : "Hi! I'm Jim" }]let output = await app.invoke ({ messages : input, language : 'chinese' }, config)console .log (output.messages [output.messages .length - 1 ].content )const input2 = [{ role : 'user' , content : 'What is my name?' }]output = await app.invoke ({ messages : input2, language : 'chinese' }, config) console .log (output.messages [output.messages .length - 1 ].content )
因为整个过程是持久化的,所以我们可以在第二次对话的时候,省略传递language参数,它会继续使用上一次的language
管理对话历史 不受限制的对话历史,可能会产生超出边界导致上下文溢出模型的token限制之类的问题,所以给对话添加消息数量限制是很有必要的
import { ChatOpenAI } from '@langchain/openai' import 'dotenv/config' import { SystemMessage , HumanMessage , AIMessage , trimMessages } from '@langchain/core/messages' import { START , END , MessagesAnnotation , StateGraph , MemorySaver } from '@langchain/langgraph' import { v4 as uuidv4 } from 'uuid' const llm = new ChatOpenAI ({ modelName : 'deepseek-r1' , openAIApiKey : process.env .API_KEY , configuration : { baseURL : process.env .BASE_URL , }, temperature : 0 }) const trimmer = trimMessages ({ maxTokens : 10 , strategy : 'last' , tokenCounter : (msgs ) => msgs.length , includeSystem : true , allowPartial : false , startOn : 'human' , }) const callModel = async (state ) => { const resultMessages = await trimmer.invoke (state.messages ) const response = await llm.invoke (resultMessages) return { messages : response } } const workflow = new StateGraph (MessagesAnnotation ) .addNode ('model' , callModel) .addEdge (START , 'model' ) .addEdge ('model' , END ) const memory = new MemorySaver ()const app = workflow.compile ({ checkpointer : memory })const config = { configurable : { thread_id : uuidv4 () } }const messages = [ new SystemMessage ("you're a good assistant" ), new HumanMessage ("hi! I'm bob" ), new AIMessage ('hi!' ), new HumanMessage ('I like vanilla ice cream' ), new AIMessage ('nice' ), new HumanMessage ('whats 2+2' ), new AIMessage ('4' ), new HumanMessage ('thanks' ), new AIMessage ('no problem!' ), new HumanMessage ('having fun?' ), new AIMessage ('yes!' ), ] const input = [...messages, { role : 'user' , content : "What's my name?" }]let output = await app.invoke ({ messages : input }, config)console .log ('output' , output.messages [output.messages .length - 1 ].content )
结果会发现最上面的"hi! I'm bob"没有在上下文中
如果询问"What's my like?"的话,就能获取到内容
当然在这个对话中多问几次之后,"What's my like?"也会不记得了🤣