LangChain 03 LangChain的一些组件
Prompt Templates 提示词模板
在LangChain中,Prompt Templates的作用是标准化和复用提示(prompt)的结构,帮助开发者将动态内容(如用户输入、上下文、示例等)高效组织成符合模型要求的输入格式,从而提升语言模型的任务适配性和输出质量。
核心作用:
- 统一提示结构,定义固定的提示格式,确保每次请求模型的输入结构一致,避免手动拼接文本导致的格式错误或不一致
- 动态内容插入,通过占位符支持灵活插入变量,适配不同场景的输入
- 减少重复代码,避免为相似任务重复编写提示文本
- 适配模型需求,根据模型特性定制模板,最大化模型表现
常见类型:
- 普通模板 PromptTemplate
- 少样本模板 FewShotPromptTemplate
- 对话模板 ChatPromptTemplate
Example Selectors 示例选择器
Example Selectors的作用是动态地从示例库中筛选出与当前输入最相关的示例,用于构建提示Prompt,从而提升语言模型在特定任务中的表现。通过插入少量示例(few-shot examples)来帮助模型理解任务格式或者上下文,动态选择最相关的示例,而非固定使用预设的示例,这样模型可以更加准确的生成符合预期的输出,避免因为示例不相关或者冗余导致的干扰。
- SemanticSimilarityExampleSelector 基于语义相似度选择与输入最接近的示例
- LengthBasedExampleSelector 根据示例长度动态调整,避免提示过长超出模型上下文限制
- MaxMarginalRelevanceExampleSelector 平衡相似性和多样性,防止选出重复或者过于接近的示例
- 自定义选择器,支持通过规则业务逻辑等筛选示例
使用场景:
- 翻译任务: 根据待翻译句子的主题选择相似的历史翻译示例
- 客服问答: 从知识库中匹配与用户问题最相关的已回答示例
- 代码生成: 依据当前代码上下文选择类似的代码片段作为参考
import {ChatPromptTemplate, FewShotPromptTemplate} from "@langchain/core/prompts" |
Chat Models 对话模型
Chat Models是专门设计用于与支持结构化消息输入的对话型语言模型交互的核心组件。
作用:
- 处理结构化消息,接收消息对象列表,而非纯文本,便于明确对话上下文和指令
- 简化对话流程,与Memory组件结合,自动管理上下文,支持流式响应
- 与langchain生态进行集成,和chains整合,统一多模型接口
- 参数控制与扩展,支持调节temperature,maxTokens等等参数,扩展处理函数,如截断过长对话历史以适应token限制
Messages 消息列表
Messages的作用是结构化地表示对话交互中的不同角色信息,以支持语言模型对上下文的理解和生成。
作用:
- 角色区分,通过不同的消息类型 HumanMessage、AIMessage、SystemMessage等,明确区分对话中用户输入、AI响应、系统指令或其他角色的内容,确保语言模型能识别信息来源
- 上下文管理,维护对话历史记录的时序和逻辑,使模型在生成回复时能参考完整的交互上下文,保持对话的连贯性
- 适配模型输入格式,结构化消息通常符合主流语言模型的API要求,简化请求数据的构建过程
- 元数据扩展,支持附加额外信息(如时间戳、用户ID或者自定义标记),供特定业务逻辑或下游任务使用,同时不影响核心对话内容
- 与框架组件集成,作为记忆系统、链Chains、代理Agents的关键输入/输出格式,确保不同模块间的数据兼容性
LLM 大语言模型
langchain中的LLM核心作用是作为底层语言模型的抽象接口,负责与预训练的大语言模型(如GPT、DeepSeek等)进行交互,将自然语言处理能力无缝集成到应用开发流程中。
作用:
- 统一模型调用,提供标准化的接口,封装不同语言模型的API调用细节,开发者无需关注底层实现差异。支持配置模型参数,控制生成结果的随机性,长度和多样性
- 文本生成和推理,根据输入文本Prompt生成连贯的输出用于问答、摘要、代码生成等场景,执行逻辑推理、数据分析等复杂任务,将非结构化文本转为结构化响应
- 上下文处理,结合Memory记忆模块,维护对话或任务的历史上下文,实现多轮交互的连贯性
- 流程编排,作为链Chains和代理Agents的组成单元,与其他工具协同工作。例如代理通过LLM决定调用哪个工具解决问题
Output Parsers 输出解析器
Output Parasers主要用于将语言模型生成的原始文本转换为结构化数据。
作用:
- 结构化输出转换,将模型返回的非结构化文本转为预定一的结构化格式如JSON、数组、对象等
- 生成格式指令,自动生成提示词Prompt,指导语言模型以特定格式输出结果,提高解析成功率
- 数据验证和错误处理,验证解析结果是否符合预期结构,并在失败时提供重试机制或抛出明确错误
- 支持复杂数据类型,处理特殊数据类型(如日期、时间、自定义对象),将其转换为Javascript可用格式
- 组合解析器,通过CombiningOutputParser合并多个解析器,处理包含多种数据类型的复杂输出
Document loaders 文档加载器
Document loaders的作用是从多样化来源高效获取并结构化文档数据,为后续语言模型处理提供基础。
作用:
- 多源支持,封装了从本地文件(文本/PDF等)、网络资源(网页/API)、云服务(AWS S3/Google Drive)及第三方应用(Notion/Airtable)等获取数据的能力
- 格式解析,自动处理不同文件格式(如PDF文本提取、HTML内容清洗、CSV结构化解析),将原始数据转化为统一文本格式
- 元数据整合,在加载过程中保留来源、创建时间等上下文信息,增强后续处理的语义关联性
- 预处理集成,支持基础文本清洗或初步分块,为后续的嵌入计算或向量存储优化数据结构
- 认证和安全,处理API密钥,OAuth等鉴权机制,保障私有数据源的安全访问
Text splitters 分词器
Text splitters的核心作用是将长文本拆分为更小的片段(chunks),以适应语言模型的输入限制、提升处理效率,并保持语义连贯性。
作用:
- 适配模型输入限制,语言模型对输入文本的Token数量有严格限制,分词器将长文本分割为符合限制的小块,确保模型能正常处理
- 保留上下文语义,通过智能分割策略,避免在句子或段落中间截断文本,减少信息断裂的风险
- 结构化文本处理,针对特定格式(如Markdown、代码、HTML),使用专用分割器(如MarkdownTextSplitter)按结构拆分,保持逻辑完整性
- 优化下游任务,分割后的文本块更适合嵌入(embedding)、向量存储或者检索增强生成(RAG),提升问答、摘要等任务的准确性
Embedding models 嵌入模型
Embedding models的核心作用是将文本转为高维向量,这些向量能够捕捉文本的语义信息。通过这种向量化表示,计算机可以更高效地处理和分析文本之间的语义相似性、相关性或差异性。
Vector stores 向量存储
Vector stores专门用于存储、管理和高效检索文本嵌入向量(Embeddings)的数据库或组件。它们和Embedding Models紧密配合,构成语义驱动应用的核心基础设施。
作用:
- 高效存储向量化数据库
- 快速相似性检索,支持高效的最近邻搜索(ANN,Approximate Nearest Neighbor),即使面对海量数据,也能快速找到与查询向量最相似的文本
- 与Embedding Models无缝集成,实现“文本 -> 向量 -> 存储 -> 检索”的一站式处理
- 支持多种存储后端,云服务(如Pinecone、Azure AI Search)、本地/轻量级(如Chroma、FAISS、MemoryVectorStore)
- 扩展复杂查询功能,元数据过滤,在检索时结合向量相似性和结构化条件。混合搜索,结合关键词匹配和语义相似性,提升召回率
- 优化大规模数据性能,索引技术使用HNSW、IVF等算法加速检索。分布式存储,支持水平扩展(如pinecone自动处理分片和负载均衡)
Retrievers 检索器
Retrievers用于从外部数据源高效获取相关信息的核心组件,尤其在处理大语言模型应用时,帮助模型突破训练数据的时间限制和知识盲区。
作用:
- 数据检索的核心引擎,负责从数据库、文档或API等外部数据源中,快速定位与用户输入相关的信息
- 与向量数据库的无缝集成,将文本通过Embedding模型转为向量,利用相似度计算查找语义相近的内容
- 支持多种检索策略,关键词检索、元数据过滤、混合检索
- 灵活扩展和定制,可以自定义Retriever,适配数据源,如企业内部数据库、CMS系统或实时API
- 上下文与对话管理,会话感知检索会结合聊天历史,优化当前查询
Indexing 索引
用于使向量数据库和底层数据源保持同步。
Tools 工具集
Tools是增强AI代理(Agent)功能的核心组件,使其能够通过调用外部工具或者执行特定操作来完成任务。
作用:
- 允许代理突破纯文本生成的限制,通过调用外部API、计算工具或自定义函数,执行动态操作
- langchain提供了多种内置工具(Build-in Tools),如:
- SerpAPITool: 通过SerpAPI执行网络搜索
- CalculatorTool: 执行数学计算
- BingSearchTool: 必应搜索集成
- WolframAlphaTool: 复杂数学或科学计算
- VectorStore检索工具: 从向量数据库中搜索相关信息
- 自定义Tools,继承Tool类,定义_call方法
Agent 代理
Agent(代理) 是一个核心组件,它充当智能决策者的角色,能够根据用户输入和上下文动态决定如何利用语言模型(LLM)和其他工具来完成任务。其核心作用是实现灵活的任务自动化与复杂问题解决,而非依赖固定的执行流程。
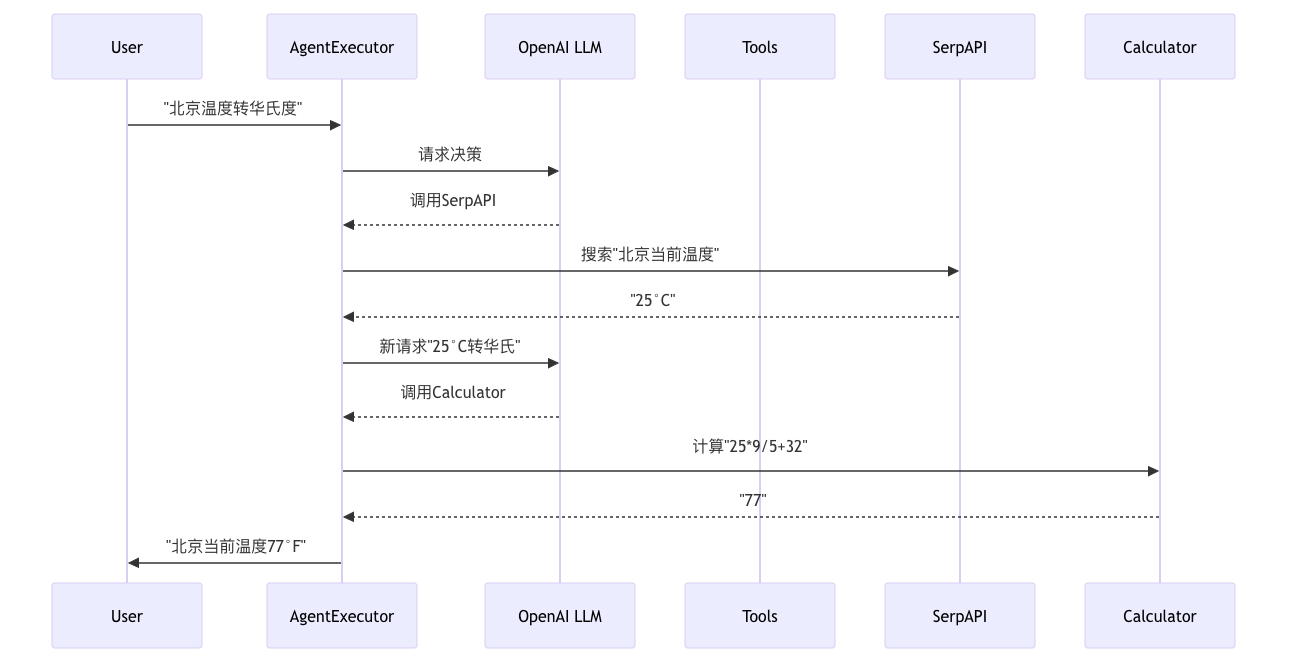
import 'dotenv/config' |
结果:
Callbacks 回调组件
Callbacks组件的作用是提供一种灵活的事件监听机制,允许开发者在大型语言模型(LLM)处理流程的关键节点注入自定义逻辑。
作用:
- 日志记录,记录请求/响应,自动捕获LLM调用的输入参数、输出结果及元数据。审计追踪,跟踪链式调用或代理的执行步骤,记录中间结果
- 监控,性能监控,统计请求延迟、Token消耗、API调用次数等指标。内容审查,检查输出是否符合安全策略(如敏感词过滤)
- 流程控制,动态干预,在生成过程中根据条件终止任务(如检测到违规内容时停止生成)。参数调整,根据中间结果实时修改模型参数(如调整temperature)
- 调试,可视化中间状态,输出Chain或Agent的推理过程,帮助定位逻辑错误
- 扩展性,集成外部系统,将结果同步到数据库、消息队列或分析平台。实现缓存机制,缓存重复请求的结果以提升性能